What is Distributed Tracing?
Modern distributed systems are built as a collection of individually developed and deployed components called microservices. A separate team can develop each service using a different programming language. They can exist as single or multiple instances running on a single host or in multiple zones and regions distributed around the globe. Those services are often run as a container inside a so-called Pod, so a scheduling system like Kubernetes can scale, update, and maintain the desired number of copies of the services.
Implemented well, microservice architectures add a lot of flexibility in terms of deployment cycles, A/B testing, team structure, development speed, technology, scalability, and reliability. However, this comes at the cost of additional complexity compared to a monolithic approach. To balance this, some choose to instead leverage “right-sized” services - sized somewhere between microservices and monoliths.
Distributed tracing is one of the essential tools for mapping and analyzing distributed services at scale, providing developers with insights to manage complexity. Distributed tracing is part of the broader concept of Observability. Distributed tracing shows how requests spread through the distributed system, showing how errors propagate and affect various components of the system and the original issuers of the requests. Though distributed tracing has existed in Application Performance Management for a long time, it became popular with the rise of microservices due to the increasing distribution. The Dapper paper, released by Google in 2010, provided concepts for a distributed tracing system that is still the basis for tracing in modern observability solutions like the tracing part of OpenTelemetry.
Distributed tracing is complemented by other signals like logs, metrics, or profiles. In concert, all the signals together can help troubleshoot problems in complex environments quickly. What distributed tracing brings to the ensemble is showing how requests spread through the distributed system and, in so doing, showing how errors propagate and affect various components of the system and the original issuers of the requests.
The OpenTelemetry Demo Application
The easiest way to understand distributed tracing is to look at a real-life example. For this, we will use the OpenTelemetry Demo application: the Astronomy Shop, a microservice-based distributed system intended to illustrate the implementation of OpenTelemetry in a near real-world environment. It consists of 15+ microservices in 12 different programming languages that communicate via HTTP and gRPC. The following graphic shows the architecture of the demo application and how the services are interacting:

The overview of OpenTelemery’s Astronomy shop as shown in Dash0: each square is a service, and the connections between services are calculated based on distributed tracing data.
Spans, the fundamental building blocks of traces
The fundamental unit of data in distributed tracing is a span. A span represents an action that a service is doing, like serving an HTTP request or sending a query to a database. To understand what spans are for, let’s first look at an example in Java that aims at measuring the execution time of a query from the point of view of the client application without using distributed tracing:
Query0return stmt.executeQuery("select COF_NAME, SUP_ID, PRICE, SALES, TOTAL from COFFEE");
If you would measure the time that the statement takes to execute, you would put in two measures before and after the Statement:
Query with Time Measurement0123456long startTime = System.nanoTime();try {return stmt.executeQuery("select COF_NAME, SUP_ID, PRICE, SALES, TOTAL from COFFEE");} finally {long duration = System.nanoTime() - startTime;// Report performance data somewhere, e.g., in a structured log or to stderr}
You will also want to know whether queries succeed if they do not, why, and what the error occurred. So your code ends up looking something like this:
Query incl Status01234567891011121314Throwable cause = null;long startTime = System.nanoTime();try {return stmt.executeQuery("select COF_NAME, SUP_ID, PRICE, SALES, TOTAL from COFFEE");} catch (Throwable t) {// Usually you would handle checked exceptions and runtime exceptions separately// with different catch blocks. This example simplifies error handling due to how// checked expressions work in Java.cause = t;throw t;} finally {long duration = System.nanoTime() - startTime;String logMessage = String.format("Query execution: %d nanos duration; failure: %s", duration, cause != null ? cause.getMessage(), "")// Report performance data somewhere, e.g., in a structured log or to stderr}
The boilerplate grows further if you want to have some additional information about the call with the timing, such as the name and type of the database, the statement executed, or the status code of the transaction. Maybe even more information about the service that executed the call: the name and version of the service, the host it was executed on, the Java version of the JVM, or the pod name. Oh, and don’t forget that you need to store this data somewhere if you need it from production, so you will start writing queries in your log analytics solution against your hand-made format. Structured logging could help you somewhat, but you know there must be a better way to do this…
Creating a Span with OpenTelemetry
Well, good news: you are right, there is a better way, and spans is precisely what you are looking for! Spans are the structured and standardized recording of the aforementioned information and more. Available not just locally but also for deployed services in production. The following code, written against the OpenTelemetry API for Java, gives not only comparable measurements of the latency of database queries but also whether they succeed or not, why they fail if they do, whether the thrown exception propagates outside of this block, and more that we will discuss later:
Query with OTel Span012345678910111213141516171819// [1] Create a new spanSpan span = tracer.spanBuilder("jdbc query").startSpan();try (Scope ignored = span.makeCurrent()) {String query = "select COF_NAME, SUP_ID, PRICE, SALES, TOTAL from COFFEE";// [2] Record which query is being executedspan.recordException(t, Attributes.of(SemanticAttributes.DB_STATEMENT, query));return stmt.executeQuery(query);} catch (Throwable t) {// Usually you would handle checked exceptions and runtime exceptions separately// with different catch blocks. This example simplifies error handling due to how// checked expressions work in Java.// [3] Record that the query execution failedspan.setStatus(StatusCode.ERROR);// [4] Record WHY the query execution failedspan.recordException(t, Attributes.of(SemanticAttributes.EXCEPTION_ESCAPED, true));throw t;} finally {// [5] Close the span and queue it for delivery to your distributed tracing systemspan.end();}
The snippet above accomplishes the following:
- Create a new span with the name jdbc query and start the time measurement.
- Save the query that will be executed as the
db.statementattribute. This is based on semantic conventions, and tools that support them can do additional analysis based on them. - If an error occurred, record that the span has failed.
- Add another semantic convention attribute that marks the throwable as “escaped”, meaning, it was not handled in this part of the application. This information is super handy when trying to understand error propagation in complex applications.
- Stop the time measurement of the span and finalize it for delivery. Note that it uses the
try-finallyidiom in Java to ensure the span is closed and if an exception propagates outside of the logic that the span wraps.
Up to this point, the recording of spans is not too dissimilar from logging, but with a terser way of recording information. Tracing’s real superpower, though, stems from its ability to represent span hierarchies!
Spans are organized into a hierarchy, called trace, with a reverse link from the child span to the parent called parent-child relation. When a span is created, if another span is active at the time, the former span is a child of the latter. For example, if you are querying a database while serving an HTTP request, the span representing the execution of the query will likely be a child of the one representing the serving of the HTTP request.
Span hierarchies across service boundaries
Parent-child relations between spans also occur between services: the span representing an HTTP interaction from the client's point of view will be the parent of the span representing the same interaction from the server's point of view. When creating the span about serving the request, the server knows which span is the parent because the instrumentation in the client has added trace context to the outgoing request i.e., has performed trace context propagation. Think of it as metadata about:
- Which trace is being recorded
- What is the currently active span (in our example, the client HTTP span)
- Other information like sampling (i.e., are we collecting tracing data for this trace or not, which is helpful to cut down on telemetry for systems with high workloads)
To illustrate what trace context propagation looks like for HTTP calls, consider the following screenshot. It shows the additional HTTP traceparent request header that an OpenTelemetry-instrumented fetch HTTP call adds to enable correlation between web browsers and backend services.

The traceparent HTTP Header was added for the correlation of spans.
Essentially, the client adds the traceparent header for the active span and trace to the outgoing request, and the server side reads the header (if available) to set the trace and parent identifiers for the server span.
This model of traces, spans and their parent-child relations, and trace context propagation is commonly observed in various distributed tracing models and is particularly well-suited for microservice-based systems, in no small part because the protocols used in cloud-native applications (HTTP, gRPC, messaging, etc.), generally support adding metadata to outgoing requests, which is used for trace context propagation. There are some exceptions, for example, protocols like AWS Kinesis, which do not support adding metadata to outgoing messages, and scenarios like batch-consumption of messages, where a single parent does not convey the right semantics. Those are advanced scenarios that we will cover in dedicated entries.
Do you need to create all spans on your own?
Well, no. Most of the time, you do not! Consider, for example, the AdService of the official OpenTelemetry Demo App. The AdService relies on automatic instrumentation to do the majority of the heavy lifting via the OpenTelemetry Java instrumentation agent, which generates spans for HTTP requests, extracts and propagates trace contexts, and identifies commonly used resource attributes. This is the OpenTelemetry spirit: enable everybody to record, modify, and transmit telemetry data while avoiding common instrumentation toil.
However, sometimes, you need to create spans for some specific piece of logic of your application to measure something very specific. This is why the AdService has this code:
AdService.getRandomAds0123456789101112131415161718192021private List<Ad> getRandomAds() {List<Ad> ads = new ArrayList<>(MAX_ADS_TO_SERVE);// create and start a new span manuallySpan span = tracer.spanBuilder("getRandomAds").startSpan();// put the span into context, so if any child span is started the parent will be set properlytry (Scope ignored = span.makeCurrent()) {Collection<Ad> allAds = adsMap.values();for (int i = 0; i < MAX_ADS_TO_SERVE; i++) {ads.add(Iterables.get(allAds, random.nextInt(allAds.size())));}span.setAttribute("app.ads.count", ads.size());} finally {span.end();}return ads;}
The app.ads.count is an important piece of information to understand how the AdService is doing its job, so it is recorded as a custom attribute (as opposed to those we saw in the JDBC example, which were all based on OpenTelemetry's semantic conventions).
Inspecting Spans in Dash0
Let’s put to good use the custom span created in each invocation of the getRemoteAds() method using Dash0:

The screenshot shows the span view of Dash0 filtered by service.name = adservice to only show the requests received by AdService. It gives a quick overview of time distribution and errors in the heatmap and a list of the spans with the most relevant information like duration or operation name.
By filtering for our getRandomAds span, we can reduce the spans to exactly the method call we have instrumented in the code snipped above.

The screenshot shows the filter for otel.span.name and a preview of available values. It offers information about how many spans will be shown when applying the filter and how many of them are erroneous, i.e., that the ERROR status code. This kind of guidance helps a lot in constructing suitable filters and often leads to insights – even before adding the filter!
Applying the filter will reduce the heatmap and list to only spans of the AdService for the getRandomAds spans.

Filtering out all spans in Dash0 that are not those custom spans from getRandomAds.
Selecting a Span will show all relevant information, including our app.ads.count attribute. It also describes the infrastructure in which the AdService method call was executed, including Java runtime, Kubernetes cluster, and AWS cloud information. This information is derived from Spans' resource attributes, which are set automatically by the Java instrumentation agent or the OpenTelemetry collector – following OpenTelemetry's semantic conventions.

The screenshot shows parts of the span detail panel, showing our custom attribute and the trace context, which gives a quick overview of the span’s position in the overall trace.
The source tab of Dash0 shows the raw span data, and we can, for example, see the attribute cloud.region with the value eu-west-1 that specifies which AWS cloud region is the span coming from. The Source tab of Dash0 provides a developer-friendly view to inspect how OpenTelemetry spans look like under the hood:
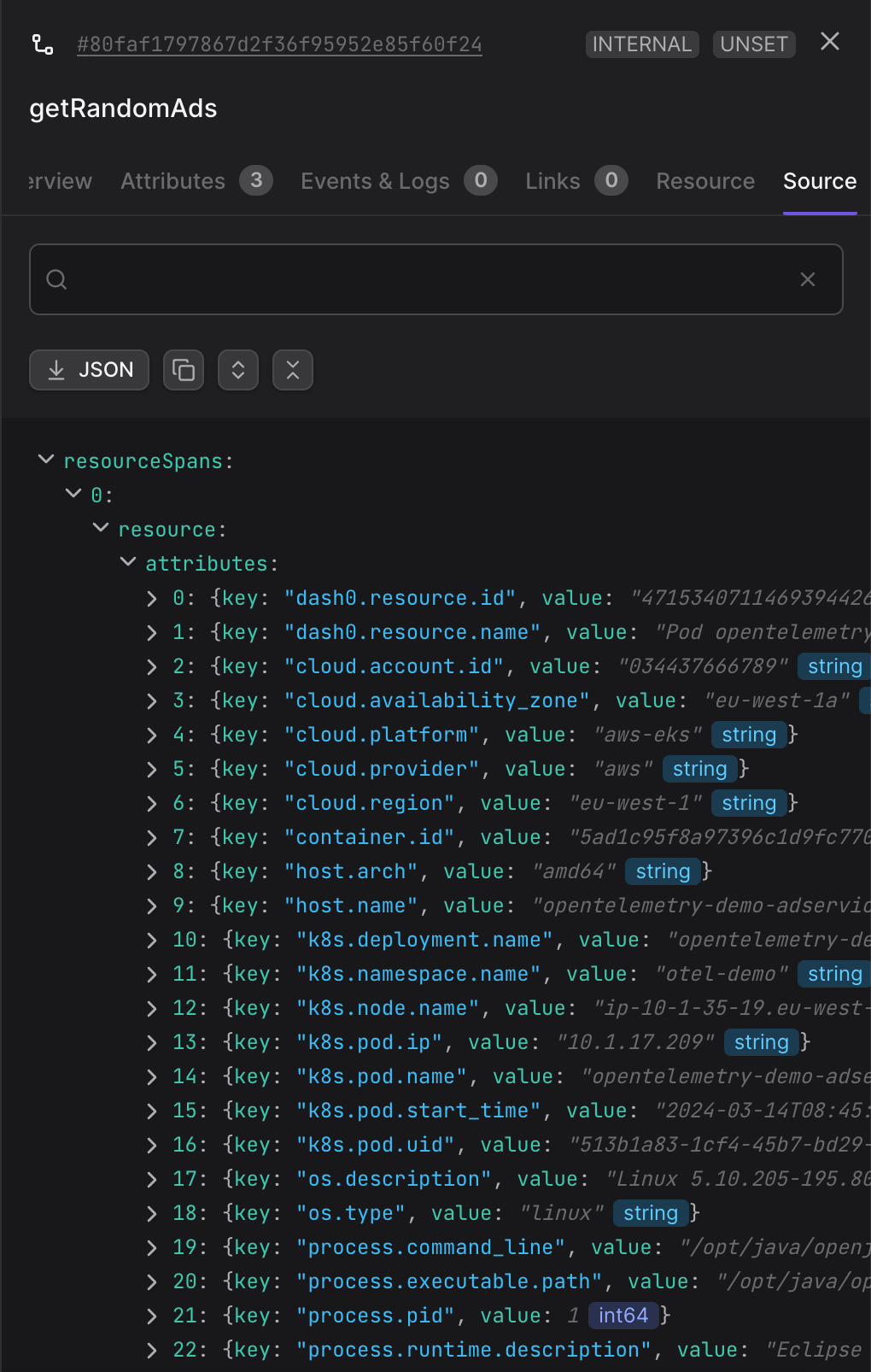
The Source panel of Dash0 facilitates the debugging process by allowing users to examine the raw data sent for the span. It is also great to learn how OpenTelemetry data structures look like!
Navigating to the trace from the span will construct and show the full trace the AdService getRandomAds method call is part of:

The trace tree in Dash0 shows the span in hierarchy and context of the full trace. Each color represents a separate resource. Events and logs are shown (including status) in the timeline of spans. The timeline section above the tree can be used to get an overview of large traces, to understand call patterns quickly and identify the critical path in the trace.
Conclusion
We have seen how to add a span to a service with few lines of code – including a custom attribute that adds additional context while debugging a problem or to add business context to it. And with the rest of the automated instrumentation of OpenTelemetry, we get a comprehensive picture of how often the method is invoked, what triggered it, including a service map that enables you to understand and navigate your service architectures quickly.
This kind of rich debugging information often makes a difference between a quick outage resolution, or a grueling troubleshooting that will probably get its own name and be told stories about.
What is the difference between distributed tracing and logging?
The main difference between tracing and logging is the hierarchy, structure, and the semantics that spans provide in addition to what logging can do:
- Hierarchy: Spans identify the call chain as part of which they were recorded. This is sometimes approximated in logs using request IDs. Spans make this reliable and standardized and work across distributed systems! As part of which HTTP request was this slow SQL statement executed? Trivial to answer with tracing!
- Structure: Spans have standardized fields to record execution times, errors and error messages (while differentiating between handled and unhandled errors), references to related data, and more. Some of this is available in a limited fashion to OpenTelemetry logs too.
- Semantics: The OpenTelemetry semantic conventions define what information needs to be recorded for HTTP, gRPC, database, and other operations. Consistency in this kind of metadata is key to have easy troubleshooting in larger applications. For more examples, see the “OpenTelemetry Resources: What they are, why you need them, and why they are awesome” recording from LEAP 2024.
All these points result in consistency and clarity when analyzing the data, sufficient context, and the ability for observability solutions to create meaningful visualizations and troubleshooting workflows beyond primitive data presentation.
If you want to, you can leverage tracing and logging together – as they work great together! Developers are used to creating logs, and in combination with OpenTelemetry's automatic instrumentation, you can get powerful troubleshooting signals with limited investment. Dash0 puts logs into the context of an entire trace by leveraging the linking between logs and traces. Using this relationship between logs and traces, developers can troubleshoot problems quickly without searching logs or spans in two different tools or data stores.

The logging view of Dash0 with a particular log highlighted. The log detail panel displays the complete trace context for the log, including which span was active when the log was created, and where does the log fit in the lifetime of the span.
What is the purpose of distributed tracing in observability?
Distributed tracing is one of multiple signals in observability. Others are metrics, logs, profiles or real user information. Distributed tracing is used to understand the interactions between services, how failure spreads, how latency builds up, and the impact on the original requesters.
Based on distributed tracing information, one can generate maps of the dependencies between services and resources (pods, host, cloud zones, etc.) and understand their relationship. This is useful for navigating and understanding large microservice applications and visualizing how workload is generated in the overall system and error propagation.
Moreover, distributed tracing is also used to provide context for metrics and logs. In isolation, logs and metrics are useful, but that usefulness is super-charged by the additional context provided by tracing, enabling the developer to aggregate them around traces and spans quickly and investigate the full trace and dependencies.
What is the best way to implement distributed tracing in microservices?
The best way to implement distributed tracing is to use the OpenTelemetry SDK for the programming language used by each component. This either means that the developer adds code for spans, as shown in the example above, or for some programming languages like Java or Python, agents are available that add the spans automatically to the code by instrumenting the code at load or runtime.
OpenTelemetry Languages and APIs & SDKs
Which tool can be used for distributed tracing in microservices?
The advantage of OpenTelemetry is that the traces can be sent to any tool that accepts OTLP-based traces. Open-source tools are available, like Jaeger or Grafanas Tempo, but there is also a large list of vendors supporting the OpenTelemetry trace signals. We recommend reading our OpenTelemetry native blog post to understand how a modern observability tool should look if built 100% around the concepts of OpenTelemetry.